A few blog posts ago I had the idea to compare the values of the fortune 500 companies. You will find the data at the end for free. Here’s how I done it.
Plan
My plan is simple. I need the core values of all Fortune 500 companies, thus I need their websites and a list of all their names. The official site features a list with subpages which feature their websites. Afterwards, I just need to check the pages for core values. Also I document these steps because a few people asked how I got the data from websites.
Let’s start crawling the URLs
I want to write a small crawler to get the URLs for each company. You can find all subpages easily on the initial HTML document, no need to load further sites or such. Let’s download it:
% wget "http://money.cnn.com/magazines/fortune/fortune500/2013/full_list/"
If you look at the code you can find that the subpages look like this:
<a href="/magazines/fortune/fortune500/2013/snapshots/54.html">
<a href="/magazines/fortune/fortune500/2013/snapshots/11719.html">
We can easily extract this URL. Generally, it’s better to use an HTML parser to extract these URL but in this case I just extract the URLs using regex. It’s sufficient for this task. If you work with data that isn’t that nicely structured or has a possibility of using special characters, use an HTML parser.
% egrep -o '<a href="(.*?\/2013/snapshots/[0-9]+\.html)">' index.html
% egrep -o '</a><a href="(.*?\/2013/snapshots/[0-9]+\.html)">' index.html | wc -l
500
The regex is straight forward. If you have questions about it write in the comments. The second line counts the matches which is a good indication that this match was successful. Now I remove the clutter and build the final URL.
% egrep -o '<a href="(.*?\/2013/snapshots/[0-9]+\.html)">' index.html | sed 's/</a><a href="//' | sed 's/">//' | sed 's/^/http:\/\/money.cnn.com/' > urls
The regex is the same. Afterwards I remove the HTML tags with sed and put the domain at first and direct the results into a text file called urls. I’m pretty sure the sed part could be improved but it works and is fast.
Getting the websites
I always start of by looking at the pages I want to crawl to find structure. It looks like that every subpage has a line like this:
Website: <a href="http://www.fedex.com" target="_blank">www.fedex.com</a>
Website: <a href="http://www.fanniemae.com" target="_blank">www.fanniemae.com</a>
Website: <a href="http://www.owenscorning.com" target="_blank">www.owenscorning.com</a>
Let’s download all the subpages and look for ourselves. Remember the urls file? I create a new directory for all the files so it doesn’t clutter my working space up and download them:
% mkdir subpages
% mv urls subpages
% cd subpages
% wget -w 1 -i urls
I limit wget to one download per second (-w 1) so that I don’t get throttled or banned. In the meantime I create the regex to test if this structure from above holds true and I want to get the company name separate:
% egrep -o 'Website: <a href="(.*?)" target="_blank">' *
% egrep -o '(.*?) - Fortune 500' *
Again I counted the results and looked at them and they looked fine. I remove the clutter again and save the data.
% egrep -o 'Website: <a href="(.*?)" target="_blank">' * | sed 's/Website: </a><a href="//' | sed 's/" target="_blank">//' > websites
% egrep -o '(.*?) - Fortune 500' * | sed 's///' | sed 's/ - Fortune 500//' > names
We need to merge these two files. I didn’t remove the file names for each grep, so that I can be sure that they got merged correctly which it did. The final line is:
% paste -d "\t" names websites | sed -E 's/[0-9]+\.html://g' > ../merged
Getting the core values
Now, I could get down and write a crawler who finds the appropriate pages (for example by googling) and extracts the values and all this stuff. But there’s a way which requires less effort. Crowd sourcing. I personally use CrowdFlower which is a great service and because amazon mechanical turk isn’t available in my country. I can use it though by proxy by using CrowdFlower.
Before I upload the file I clean it up. There where some errors in it, e.g. a comma instead of a dot in URL. Then I encased each site by quotes and replaced escaped / replaced characters like quotes. Afterwards I replaced the tabs by commas to make it a csv and added headers.
CrowdFlower offers templates for different jobs. I just created my own. You basically just write an instruction and then create your form. I collected the URL and core values / core beliefs.
The first time I worked with CrowdFlower it may take me 60 minutes to set the task up. Now it takes about 20 minutes. You can’t expect perfect results using crowd sourcing. Some people will limit their effort, other people are extremely diligent. But even if you work with other people you can’t expect perfect results.
Thus the fun part begins where I check the data. I won’t check every detail because this is just for a blog post and not for research purposes. Also, the next time I would change the design of the tasks a bit. But it only costs me about $60 (about 12c per company) and I get the results in less than 4 hours, so I don’t really care.
My initial design was to give the workers the company’s URL and let them find the core values / core believes. The next time I would link to Google with ‘site: “core values”‘ and vice versa with core beliefs. I found this out that some companies have values that only appear in pdfs of their annual report. I didn’t expect the works to look there. Thus, the data will be quite incomplete. Yet, this wasn’t really my initial goal.
What is your goal btw?
Good to talk about that. While I wrote the blog post mention above I thought about how all companies basically have the same values. I expect that some values are very common (>60% of all companies have them). And that there are very few companies, if one at all, who has a unique set of values.
Data cleaning
The fun part. You can download the data directly from CrowdFlower in csv or json. I use the csv file. Trying to import to excel doesn’t really work because excel doesn’t handle the multiline comments correctly. A simple solution is to use R and the xlsx package.
dat write.xlsx(dat, "answers.xls")
The import works pretty fine and even the characters aren’t fucked up. To make the text more readable I change the cells format to wrap text (alignment tab) and clean up the spreadsheet a bit.
I check a few of the entries and correct them, however I don’t try to achieve the highest accuracy but enough for a fun Sunday data project.
Now it’s time to categorize the values. There are various ways: crowd sourcing it, measuring the frequency of words to extract values and then categorize them, using a dictionary with values, etc. I just do it by hand. I took me about 3 hours to categorize all entries. Some responses of the workers were false. I wonder if they had problems understand looking for core values or they just didn’t care. There are quite a lot missing.
Somehow, I took the time to do them by hand. That was quite a lot of work (about 2 hours) but I’m quite happy.
Look at the data
Of the 500 companies I have data for 328 companies (n=328). I grouped them by 60 categories. You can download the data here: data.csv. It is a bit messed up (i.e. I somehow set at least a wrong x because there isn’t a company with diligence as value although there is one).
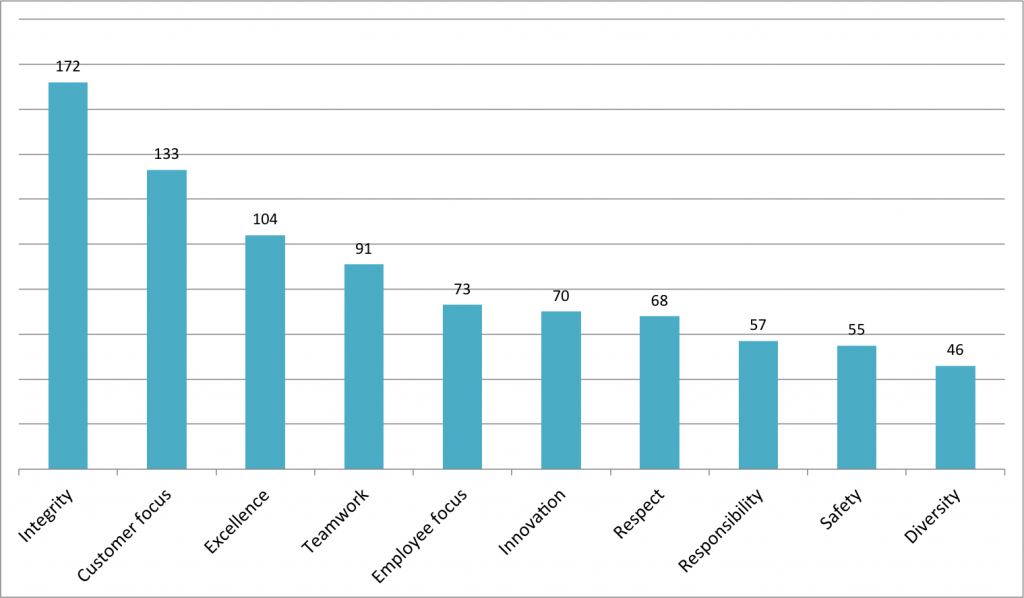 These are the most used values. Over half of the companies state integrity as their value. Customer focus is quite strong and excellence (32%). This is was I expected. Interesting was that only 2 companies stated effectiveness and 8 efficiency. However, a lot of companies talked about hard work. I’m personally more on the side of smart work but I’m not surprised.
These are the most used values. Over half of the companies state integrity as their value. Customer focus is quite strong and excellence (32%). This is was I expected. Interesting was that only 2 companies stated effectiveness and 8 efficiency. However, a lot of companies talked about hard work. I’m personally more on the side of smart work but I’m not surprised.
Some of the lesser stated values were honor, objectivity and authenticity. Also there wasn’t a company with unique set of values.The data wasn’t that interesting. It could be interesting if you compare stated and lived values. Yet, I’m happy that I’m done. I started today at 9 a.m. and now I’m finished at 11 p.m. I relaxed a few hours but that was basically my project for today. Quite an effort for my initial question.


