
Algorithm 5.2: Given a randomly ordered set of n integers, sort them into non-descending order using the selection sort.
So implementing selection sort. Should be easy, let’s see.
(defn selection-sort
"Does selection sort on a vector"
[numvector]
(when (seq numvector)
(let [minimum (apply min numvector)
new-vector (remove (set [minimum]) (set numvector))]
(conj (selection-sort new-vector) minimum))))
Was easy enough. Not quite as nice as writing it in Haskell but okay. The idea is that we take the smallest element put it in front, then repeat this until our list is empty. This is a bit different from the ‘traditional’ implementation which swaps the minimum result with that at the current lowest unsorted index. But the idea is the same.
Algorithm 5.6: Sorting by Partitioning. Implement quicksort.
I love quicksort. It’s such an easy and efficient algorithm.
(defn qsort [[pivot & unsorted]]
"A classical implementation of quicksort"
(when pivot
(let [smaller #(< % pivot)]
(lazy-cat
(qsort (filter smaller unsorted))
[pivot]
(qsort (remove smaller unsorted))))))
Look at that beautiful algorithm. The idea is that you take a pivot – often the first element and create a new list which consists of elements smaller as the pivot, the pivot, and elements larger than the pivot. And you just apply quicksort to these other lists. That’s it.
Algorithm 6.1 Given a set of lines of text of arbitrary length, reformat the text so that no lines of more than n characters are printed. In each output line the maximum number of words that occupy less than n characters, should be printed and no world should extend across two lines. Paragraphs should also remain indented.
Good old textwrap. Let’s take a look at an example.
This is a sentence which is quite long
Imagine that we want to have n = 10. In this case the output is
This is a
sentence
which is
quite long
We don’t want to break words which is problematic in case the word is longer than n.
(defn wrap-word
"Returns the sentence as strings with maxium length of n.
Beware: Doesn't cut words, i.e. the largest word has to be
smaller than n"
[sentence n]
(let [split-sentence (interleave (clojure.string/split sentence #" ") (repeat " "))]
(loop [rest-sentence split-sentence
result nil
tmp-sentence nil
current-length 0]
(if (seq rest-sentence)
(let [current-word (first rest-sentence)
word-length (count current-word)]
(if (<= (+ current-length word-length) n)
(recur (next rest-sentence) result (concat tmp-sentence current-word) (+ current-length word-length))
(recur rest-sentence (conj result tmp-sentence) nil 0)))
(conj result tmp-sentence)))))
I’m quite tired right now but a short explanation before going to bed. The software starts by splitting the current string into words and rebuilding the string with whitespaces. E.g. “ABC DEF” -> “ABC” ” ” “DEF”. Afterwards, it does two things:
a) In case the current-length of the temporary sentence is less than n -> append new word
b) In case the current-length is bigger, append the temporary sentence to the output and start with a new word
Here’s the example from above:
user=> (map #(apply str %) (wrap-word "This is a sentence which is quite long" 10))
(" " "quite long" "which is " "sentence " "This is a ")
You can see that it forms:
This is a
sentence
which is
quite long
Exactly like above.
 for n >= 0
for n >= 0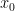 :
: 