
Yeah, new book series! I had laying this book around for about two and an half years and only read about a quarter of it but never worked through it. So, I decided to work through it and post interesting problems and solutions online.
The book consists of two parts. The first part treats the algorithmic basics. The second part is just a reference of different algorithmic problems and ways to solve it. I won’t cover the second part, mainly because there are no exercises.
1-1. Show that a + b can be less than min(a, b).
Solution: 1-1. For any 
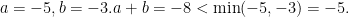
1-2. Show that a × b can be less than min(a, b).
Solution For example for 


1-5. The knapsack problem is as follows: given a set of integers 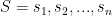
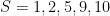

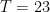
Find counterexamples to each of the following algorithms for the knapsack problem. That is, giving an S and T such that the subset is selected using the algorithm does not leave the knapsack completely full, even though such a solution exists.
(a) Put the elements of S in the knapsack in left to right order if they fit, i.e. the first-fit algorithm.
(b) Put the elements of S in the knapsack from smallest to largest, i.e. the best-fit algorithm.
(c) Put the elements of S in the knapsack from largest to smallest.
Solution:
(a)
(b)
(c)


1-16. Prove by induction that n3 + 2n is divisible by 3 for all n ≥ 0.
Solution: The base case is 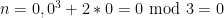
We can assume that this holds up to n. For n + 1 we get:
The first term is parenthesis is our assumption and the second term is obviously divisible by 3, therefore we showed that our assumption is true.

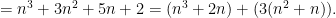
1-26. Implement the two TSP heuristics of Section 1.1 (page 5). Which of them gives better-quality solutions in practice? Can you devise a heuristic that works better than both of them?
Solution:
from random import randint
class Point:
def __init__(self, ID, x, y):
self.ID = ID
self.x = x
self.y = y
def distance(self, other):
return ( (self.x - other.x) ** 2 + (self.y - other.y) ** 2 ) ** 0.5
def closestPoint(P, visited, p):
shortestDistance = float("Inf")
shortestPoint = None
for pi in P:
if visited[pi.ID] == False:
if p.distance(pi) < shortestDistance:
shortestDistance = p.distance(pi)
shortestPoint = pi
return shortestPoint
def nearestNeighbour(P):
visited = [False] * ( len(P) + 1) # ID starts with 1
p = P[0]
visited[0] = True # not existing
visited[1] = True # first node
i = 0
finalPath = [p]
while False in visited:
i += 1
pi = closestPoint(P, visited, p)
if pi == None: # last point
break
visited[pi.ID] = True
p = pi
finalPath.append(p)
finalPath.append(P[0])
return finalPath
def closestPair(P):
n = len(P)
finalPath = []
vertexChain = [[p] for p in P]
d = float("INF")
for i in xrange(1, n-1):
d = float("INF")
for i1, v1 in enumerate(vertexChain):
for i2, v2 in enumerate(vertexChain):
if i1 != i2:
s = v1[-1]
t = v2[-1]
if s.distance(t) <= d:
sm = i1
tm = i2
d = s.distance(t)
vertexChain[sm] += vertexChain[tm]
vertexChain.pop(tm)
vertexChain[0] += vertexChain.pop(1)
return vertexChain[0]
return finalPath
def getPathSum(P):
distance = 0
for i in xrange(1, len(P)):
distance += ((P[i].x - P[i-1].x) ** 2 + (P[i].y - P[i-1].y) ** 2)
return distance ** 0.5
P_rect = [Point(1, 0, 0), Point(2, 0, 5), Point(3, 5, 0), Point(4, 5, 5)]
P_line = [Point(1, 0, 5), Point(2, 0, 0), Point(3, 0, 10), Point(3, 0, 15)]
P_rand = [Point(i, randint(0, 15), randint(0,15)) for i in xrange(0, 10)]
print "**Rectangle**"
print "> NearestNeighbour: %i" % getPathSum(nearestNeighbour(P_rect))
print "> ClosestPair: %i" % getPathSum(closestPair(P_rect))
print "**Line**"
print "> NearestNeighbour: %i" % getPathSum(nearestNeighbour(P_line))
print "> ClosestPair: %i" % getPathSum(closestPair(P_line))
print "**Rand**"
print "> NearestNeighbour: %i" % getPathSum(nearestNeighbour(P_rand))
print "> ClosestPair: %i" % getPathSum(closestPair(P_rand))
NearestNeighbour createst shorter paths for small input graphs. For midsize input paths and big input graphs closestPair creates smaller paths. However nearestNeighbour is much faster. In conclusion, it depends on the application which heuristic is more suitable.
1-28. Write a function to perform integer division without using either the / or * operators. Find a fast way to do it.
Solution: A simple way to perform integer division is substracting the divisor and counting each substraction. This only works for positive numbers. (more in the comments)
def divideBySub(a, b):
count = 0
while a >= 0:
a -= b
count += 1
return count
If we can find a bigger divisor we could speed it up. An easy way is to multipy the divisor by itself as long as it divides the denominator with a rest.
def divideBySubFaster(a, b):
countB = 0
lastB = b
while a % b == 0:
lastB = b
b += b
countB += 1
b -= lastB # revert last change
countB -= 1 # revert last change
result = divideBySub(a, b)
for i in xrange(0, countB):
result += result
return result
This works quite nice and can speed up the process substantially.