
Again, some older post I had lying around. Nonetheless, the topic is still prevalent.
I recently read a great paper named To Explain or To Predict? by Galit Shmueli. She explains the differences between the “old-school” explanatory statistics and predictive statistics. I saw lots of her observations by myself.
That means predictions are often regarded as unscientific and therefore there’s a bit of a lack of good literature – lately the situation became better with the uprising of machine learning.
Nonetheless, most students don’t learn how to make predictions and you see how people use 
Sure, there are some departments that teach how to predict but they are still in the minority. Of course, there’s this other trend with Big Data. I’m personally not really excited by Big Data rather by data at all.
More Info: http://galitshmueli.com/explain-predict
I wrote this post more than 2 years ago. Now machine learning became some kind of commodity on a smaller level and something strange happened. Some of the people who work with data but didn’t learn good statistical techniques started to try to explain data which is pretty terrible. It even seems that they try to reinvent statistics. I read a post yesterday called Why big data is in trouble: they forgot about applied statistics which captured this pretty nicely.
The table at the bottom is just unbelievable. It lists different fields and the application of “big data” or “data science”. They also list that in 2012 they finally start to enter fields like biology, economics, engineering, etc. Which is more sad than hilarious. So yeah, I didn’t expect this turn.
Furthermore, I saw more and more “data science” boot camps / programs popping up. Still neglecting statistical foundations. Resulting in even more terrible studies. This trend will probably follow the Gartner Hype Cycle. As far as I can tell the peak is already reached, now it will begin to be disappointing and in a few years actually reach its plateau. Here the latest Hype Cycle from July 2013:
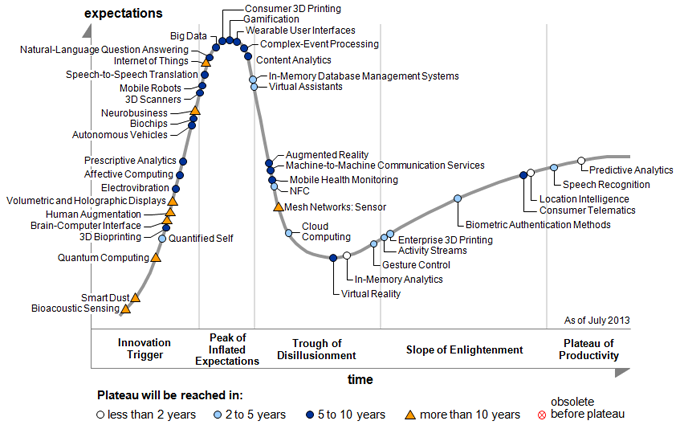
I see the term “prescriptive analytics” on there and just looked it up. It’s astonishing that people reinvent new terms for so much stuff and it still works. Even stuff like business intelligence is basic statistics, then came predictive analysis (still statistics), data science (hey statistics), now prescriptive analytics (still statistics).
I just have to quote one of my favorite quotes on this topic:
Someone (can’t recall the source, sorry) recently defined “data scientist” as “a data analyst who lives in California.” —baconner


