I remember a post on hacker news about 4 years ago about some guy who build a cool app where he examined when you should ideally post on hacker news to get your post to the front page. He recommended one book called Data Mining Cookbook by Olivia Paar Rud. I had a copy lying around since then and never looked at it.
Chapter 1
She describes using genetic programming for model selection. I found this idea really interesting and actually never saw it. I may try it out.
Chapter 2: Selecting the Data
Offer History Database: The idea is to log all offers you made to a specific person. You can track the customer id, campaign id and the response.
If you build a new model look if the data is filtered. Also an interesting observation. If you use data which was pre-selected you can’t really build a model on the whole population.
If you have multiple mailings to smaller groups. For example you are mailing 50k prospects, then the 50% based on some score and then again the best 25%. You can combine the data together and then create columns for each response. You can still build your models however the probability is no longer correct, ranking still works.
Chapter 4: Selecting and transforming the variables
Find interactions with tree-based algorithms and use them in your logistic models
Chapter 6: Validating the model
For discrete outcomes: Sort by model score and create percentile groups; compare outcomes and attributes in these groups
Chapter 7: Implementing and maintaining the model
Calculate the model life-time and recheck every period
Chapter 8: Understanding your customer: Profiling and Segmentation
Market-driven segmentation: use customer attributes to segment your data
Penetration analysis: compare demographic data of your customers against your market. Calculate your penetration index (% market / % customer) * 100 and try to acquire more customers in the segments where your penetration index is the highest
Customer Value Analysis: 2×2 matrix (risk vs. revenue) then split up each cell into its demographics and/or behavioral attributes which can lead to groups like “business builders” or “Risky Revenue”
Chapter 9: Target New Prospects: Modeling Response
For each continuous attribute check if there are possible segments and transformations; regress with stepwise on your outcome and select best fitting variables
Chapter 12: Targeting Profitable Customers: Modeling Lifetime Value
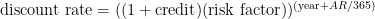
Conclusion
The book was written in 2001 and for that it’s fantastic. I was too young to be interested in data mining or analytics in 2001 but if I had been older this book would have been a gem. If you never worked with data before I can recommend this book to you. The author focuses less on the model (she uses mainly logistic regressions, stepwise, best subset) and more on the work around models. That is finding outliers, fixing missings, finding good attributes and presenting the results. In my opinion most books neglect this and lots of beginners know about SVMs and Random Forests but have no idea how to properly apply them.