
Algorithm 8.4: Design an algorithm that generates all permutations of the first n integers taken r at a time and allowing unrestricted repetitions. This is sometimes referred to as sample generation. The values of n and r must be greater than zero.
This was also something I never did properly, writing combinatorial algorithms. I want to clean up and do it finally.
So the problem is that we want these permutations of integers. Given n = 4 and r = 2, we get:
1 1 1 2 1 3 1 4 2 1 2 2 2 3 2 4 3 1 3 2 3 3 3 4 4 1 4 2 4 3 4 4
These are 
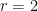
user=> (for [x (range 1 6) y (range 1 6)] [x y]) ([1 1] [1 2] [1 3] [1 4] [1 5] [2 1] [2 2] [2 3] [2 4] [2 5] [3 1] [3 2] [3 3] [3 4] [3 5] [4 1] [4 2] [4 3] [4 4] [4 5] [5 1] [5 2] [5 3] [5 4] [5 5])
We iterate over every x and every y. We could write a macro which just creates more variables given r. But let’s take a more general view.
We can see that the sequence [1 2 3 4] is repeated over and over again. The only thing that changes is the first number. More generally, we combine our first number with all the sub-permutations, then our second number, etc.
(defn generate-sample
"Implements the sample generation algorithm
which produces permutations of n integers
with length r"
[n r]
{:pre [(pos? n) (pos? r)]}
(let [numbers (range 1 (inc n))]
(loop [result (map vector numbers)
new-r r]
(if (> new-r 1)
(recur
(apply
concat
(for [idx numbers]
(map #(conj % idx) result)))
(dec new-r))
result))))
Again, no super hard code. We basically iterate over our existing result set and append the integers up to n to each one and then do it again recursively. I’m surprised that it was that easy :D
And here’s some output:
user=> (generate-sample 4 1) ([1] [2] [3] [4]) user=> (generate-sample 4 2) ([1 1] [2 1] [3 1] [4 1] [1 2] [2 2] [3 2] [4 2] [1 3] [2 3] [3 3] [4 3] [1 4] [2 4] [3 4] [4 4]) user=> (generate-sample 4 3) ([1 1 1] [2 1 1] [3 1 1] [4 1 1] [1 2 1] [2 2 1] [3 2 1] [4 2 1] [1 3 1] [2 3 1] [3 3 1] [4 3 1] [1 4 1] [2 4 1] [3 4 1] [4 4 1] [1 1 2] [2 1 2] [3 1 2] [4 1 2] [1 2 2] [2 2 2] [3 2 2] [4 2 2] [1 3 2] [2 3 2] [3 3 2] [4 3 2] [1 4 2] [2 4 2] [3 4 2] [4 4 2] [1 1 3] [2 1 3] [3 1 3] [4 1 3] [1 2 3] [2 2 3] [3 2 3] [4 2 3] [1 3 3] [2 3 3] [3 3 3] [4 3 3] [1 4 3] [2 4 3] [3 4 3] [4 4 3] [1 1 4] [2 1 4] [3 1 4] [4 1 4] [1 2 4] [2 2 4] [3 2 4] [4 2 4] [1 3 4] [2 3 4] [3 3 4] [4 3 4] [1 4 4] [2 4 4] [3 4 4] [4 4 4])