
8-2. Suppose you are given three strings of characters: X, Y , and Z, where |X| = n, |Y|=m,and|Z|=n+m.Z is said to be a shuffle of X and Y iff Z can be formed by interleaving the characters from X and Y in a way that maintains the left-to-right ordering of the characters from each string.
(a) Show that cchocohilaptes is a shuffle of chocolate and chips, but chocochilatspe is not.
(b) Give an efficient dynamic-programming algorithm that determines whether Z is a shuffle of X and Y . Hint: the values of the dynamic programming matrix you construct should be Boolean, not numeric.
Solution (a) We can start from the end and move forwards to the beginning. You can check cchocohilaptes for yourself. If you check chocochilatspe you take the last letter from chocolate, i.e. the next letter could be s or t but it is p, therefore it isn’t a shuffle.
(b)
X = "chocolate"
Y = "chips"
Z1 = "cchocohilaptes"
Z2 = "chocochilatspe"
def isShuffel(X, Y, Z):
if not Z:
return True
if Z[-1:] not in [X[-1:], Y[-1:]]:
return False
if Y[-1:] == X[-1:]: # two possibilites
fst = isShuffel(X[:-1], Y, Z[:-1])
snd = isShuffel(X, Y[:-1], Z[:-1])
if fst:
return fst
elif snd:
return snd
else:
return False
elif Z[-1:] == X[-1:]:
return isShuffel(X[:-1], Y, Z[:-1])
elif Z[-1:] == Y[-1:]:
return isShuffel(X, Y[:-1], Z[:-1])
print isShuffel(X, Y, Z1)
print isShuffel(X, Y, Z2)
Here’s the general idea behind the algorithm. I haven’t implemented the DP solution, mainly because it would make the code messier. Instead of using list slicing, I would work with indicies for X, Y and Z. With this method we can easily construct a n x m x (n+m) Matrix which saves the return value of isShuffel for the needed values. If we work with memoization, we can speed the whole process substainally for larger words.
8-5. Let P1,P2,…,Pn be n programs to be stored on a disk with capacity D megabytes. Program Pi requires si megabytes of storage. We cannot store them all because
(a) Does a greedy algorithm that selects programs in order of nondecreasing si maximize the number of programs held on the disk? Prove or give a counter- example.
(b) Does a greedy algorithm that selects programs in order of nonincreasing order si use as much of the capacity of the disk as possible? Prove or give a counter- example.

Solution (a) Assume that it doesn’t. That is, we can take two Programs 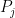
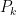
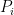
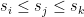
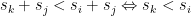
(b) We can easily construct a counter-example. Let’s say we got the following four programs:
Program i space s 1 2 2 3 3 4 4 5
And there should be a capacity of 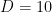

8-6. Coins in the United States are minted with denominations of 1, 5, 10, 25, and 50 cents. Now consider a country whose coins are minted with denominations of {d1,…,dk} units. We seek an algorithm to make change of n units using the minimum number of coins for this country.
(a) The greedy algorithm repeatedly selects the biggest coin no bigger than the amount to be changed and repeats until it is zero. Show that the greedy algorithm does not always use the minimum number of coins in a country whose denominations are {1, 6, 10}.
(b) Give an efficient algorithm that correctly determines the minimum number of coins needed to make change of n units using denominations {d1,…,dk}. Analyze its running time.
Solution (a) Take for example 12. The algorithm uses 10, 1 and 1. A shorter possibility is 6 and 6.
(b) I start with using the example case from (a). We can construct the following graph.

The optimal solution is that one with the shortest path. However, this requires a lot of time therefore we try to use some sort of dynamic programming.
Instead of constructing a whole tree we construct multiples for each value up to n. You can see here why:

We got multiple reoccurences therefore it is suitable for dynamic programming. How should our calculation look like?
n Coins 1 1 2 1, 1 3 1, 1, 1 4 1, 1, 1, 1 5 1, 1, 1, 1, 1 6 6 7 6, 1 8 6, 1, 1 9 6, 1, 1, 1 10 10 11 10, 1 12 6, 6 13 6, 6, 1 .. ..
The beauty is that we can look up smaller values for computing an n. Let’s take n = 12 as an example.
We start with the smallest value and search for the smallest combination.
Calculation Coins? #Coins 12 - 1 = 11 1 & 10, 1 1 + 2 = 3 12 - 6 = 6 6 & 6 1 + 1 = 2 12 - 10 = 2 10 & 1, 1 1 + 2 = 3
Therefore our reoccurence looks like:
Where C[n] is the minimum amount of coins. Our base case is ![C[0] = 0](http://s0.wp.com/latex.php?latex=C%5B0%5D+%3D+0&bg=ffffff&fg=000&s=0&c=20201002)
Now to the complexity. For each n we need 
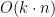
![C[n] = 1 + min_{\forall d_i \in \{d_1,...,d_k\}} C[n - d_i]](http://s0.wp.com/latex.php?latex=C%5Bn%5D+%3D+1+%2B+min_%7B%5Cforall+d_i+%5Cin+%5C%7Bd_1%2C...%2Cd_k%5C%7D%7D+C%5Bn+-+d_i%5D&bg=ffffff&fg=000&s=0&c=20201002)
8-9. The knapsack problem is as follows: given a set of integers S = {s1, s2, . . . , sn}, and a given target number T, find a subset of S that adds up exactly to T. For example, within S = {1,2,5,9,10} there is a subset that adds up to T = 22 but not T = 23.
Solution Basically similar to the coin problem but with constrains. We can construct the following table/matrix:
T calculation elements of S 1 1 - 1 1 2 2 - 2 2 3 3 - 2 = 1 - 1 2, 1 4 4 - 1 = 3 None, because 1 will be used* 5 5 - 5 5 6 6 - 5 = 1 5, 1 7 7 - 5 = 2 5, 2 8 8-5=3-2=1 5, 3, 1 9 9 None, 8 uses all elements < 10 10 10 - 10 10 11 11 - 10 = 1 10, 1 ...
* We test each 
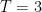

For each row we need at most 2n calculations and checks. We got T rows therefore our construction time is

8-10. The integer partition takes a set of positive integers S = s1, . . . , sn and asks if
there is a subset I ∈ S such that
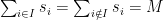
Give an O(nM) dynamic programming algorithm to solve the integer partition problem.
Solution We can use the solution of the knapsack problem for this exercise. We know that each partition should be 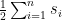
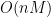
8-13. Consider the following data compression technique. We have a table of m text strings, each at most k in length. We want to encode a data string D of length n using as few text strings as possible. For example, if our table contains (a,ba,abab,b) and the data string is bababbaababa, the best way to encode it is (b,abab,ba,abab,a)— a total of five code words. Give an O(nmk) algorithm to find the length of the best encoding. You may assume that every string has at least one encoding in terms of the table.
Solution We can again use a typical dynamic programming approach were we use memoization to save and generate substrings. We try every permutation, i.e. we will get the correct solution.
8-15. Eggs break when dropped from great enough height. Specifically, there must be a floor f in any sufficiently tall building such that an egg dropped from the fth floor breaks, but one dropped from the (f − 1)st floor will not. If the egg always breaks, then f = 1. If the egg never breaks, then f = n + 1.
You seek to find the critical floor f using an n-story building. The only operation you can perform is to drop an egg off some floor and see what happens. You start out with k eggs, and seek to drop eggs as few times as possible. Broken eggs cannot be reused. Let E(k,n) be the minimum number of egg droppings that will always suffice.
(a) Show that E(1, n) = n.
(b) Show that E(k,n) = Θ(nk ).
(c) Find a recurrence for E(k,n). What is the running time of the dynamic program to find E(k, n)?
Solution (a) We got only one egg, so the only strategy to find the fth floor is to start at the first and try each consecutive floor. This leads to
(b) The idea is to use some kind of binary search. We can half the interval for each k – 1. We use the last egg to test our last interval. Therefore 

(c) 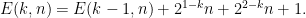
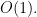
8-16. Consider a city whose streets are defined by an X × Y grid. We are interested in walking from the upper left-hand corner of the grid to the lower right-hand corner.
Unfortunately, the city has bad neighborhoods, whose intersections we do not want to walk in. We are given an X × Y matrix BAD, where BAD[i,j] = “yes” if and only if the intersection between streets i and j is in a neighborhood to avoid.
(a) Give an example of the contents of BAD such that there is no path across the grid avoiding bad neighborhoods.
(b) Give an O(XY ) algorithm to find a path across the grid that avoids bad neighborhoods.
(c) Give an O(XY ) algorithm to find the shortest path across the grid that avoids bad neighborhoods. You may assume that all blocks are of equal length. For partial credit, give an O(X2Y 2) algorithm.
Solution (a) B means BAD, G means good
GBB BBG
(b) We can implement a basic breath first backtracking algorithm which visits each block no more than one time. Backtracking, visited array, each i, j is visited one time. That is, we start at the higher left corner and put each adjacent block in a queue. If we visited the lower right corner we found a path otherwise if we have visited every adjacent block and not have visited the lower right corner then there’s no path.
(c) We can use a modified version of (b) for this task. We start with an extra cost matrix which is initialized with 0 for each not bad block and ‘X’ otherwise. If we start at an arbitrary block [k, l] and put its adjacent blocks on our queue, we set their cost entry to C[k,l] + 1. At the end, we get a cost matrix which allows us to find the shortest paths.
But let’s look at an example first.
G G B G B G 0 1 X 7 X 9 B G B G G G X 2 X 6 7 8 B G G G B G X 3 4 5 X 9 G B G B B G 0 X 5 X X 10
On the right is the initial matrix and on the right is the cost matrix. We can easily find the shortest path by starting at [i, j] and traverse backwards by choosing the next block which got one cost less than the current one.
8-17. Consider the same situation as the previous problem. We have a city whose streets are defined by an X × Y grid. We are interested in walking from the upper left-hand corner of the grid to the lower right-hand corner. We are given an X × Y matrix BAD, where BAD[i,j] = “yes” if and only if the intersection between streets i and j is somewhere we want to avoid.
If there were no bad neighborhoods to contend with, the shortest path across the grid would have length (X − 1) + (Y − 1) blocks, and indeed there would be many such paths across the grid. Each path would consist of only rightward and downward moves.
Give an algorithm that takes the array BAD and returns the number of safe paths of length X + Y − 2. For full credit, your algorithm must run in O(XY ).
Solution Let’s start with an example with three paths of length X + Y – 2.
G G G G G 0 1 2 3 4 G G B G G 1 2 X 4 5 G B G B G 2 X 6 X 6 G G G G G 3 4 5 6 7
We started with costs 0 at [0, 0] therefore we got X + Y – 2 – 1 as shortest paths. We know that each valid path is characterized by its costs 0 to X + Y – 2 – 1. Therefore we just have to count how often the full set exists. E.g. we count for each number its occurrence with an array and afterwards find the smallest amount of occurrences which is the number of paths.
8-18. Consider the problem of storing n books on shelves in a library. The order of the books is fixed by the cataloging system and so cannot be rearranged. Therefore, we can speak of a book bi, where 1 ≤ i ≤ n, that has a thickness ti and height hi. The length of each bookshelf at this library is L.
Suppose all the books have the same height h (i.e. , h = hi = hj for all i,j) and the shelves are all separated by a distance of greater than h, so any book fits on any shelf. The greedy algorithm would fill the first shelf with as many books as we can until we get the smallest i such that bi does not fit, and then repeat with subsequent shelves. Show that the greedy algorithm always finds the optimal shelf placement, and analyze its time complexity.
Solution We can’t rearrange books, therefore we have to think about the alternatives to the greedy algorithm. Permutations aren’t allowed, i.e. the only thing we can control is how many books we put into each shelves. We want to minimize the space therefore we want to put as much books as possible in the shelves. That’s exactly what the greedy algorithm does.
8-24. Given a set of coin denominators, find the minimum number of coins to make a certain amount of change.
Solution See 8-6.
8-25. You are given an array of n numbers, each of which may be positive, negative, or zero. Give an efficient algorithm to identify the index positions i and j to the maximum sum of the ith through jth numbers.
Solution We can implement a pretty naive algorithm which tests every possibility.
max := array[1]
for i := 1 to n
for j := i to n
sum := calculateSum(i, j)
if sum > max
max := sum
where calculateSum(i,j) looks like:
function calculateSum(i, j)
sum := 0
for k := i to j
sum := sum + array[k]
We can speed up calculateSum() using a matrix which saves the sum from i to j as M[i, j]. There are three possibilites to calculate this:
(1) M[i, j] = i + M[i - 1, j] if i > 1 (2) M[i, j] = M[i, j - 1] + j if j > 1 (3) M[i, j] = i + M[i - 1, j - 1] + j if i > 1 and j > 1
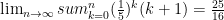 calls. Therefore we need
calls. Therefore we need 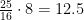 calls for our rng07.
calls for our rng07.
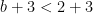 , i.e.
, i.e. ![e \in [0, 2] \setminus \{1, 2\}.](http://s0.wp.com/latex.php?latex=e+%5Cin+%5B0%2C+2%5D+%5Csetminus+%5C%7B1%2C+2%5C%7D.&bg=ffffff&fg=000&s=0&c=20201002) In conclusion, the MST isn’t the shortest path if
In conclusion, the MST isn’t the shortest path if 

 .
.
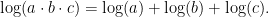

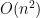 time.
time.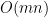 for initializing the matrix and the loop needs
for initializing the matrix and the loop needs 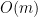 therefore the algorithm needs
therefore the algorithm needs 

